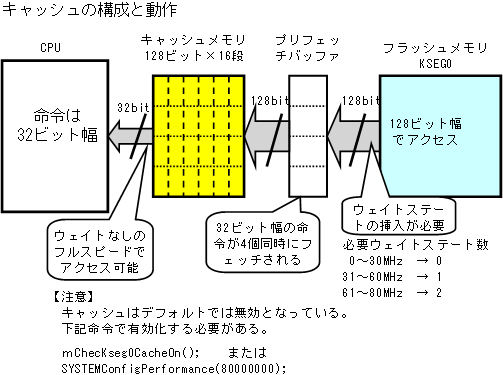
【キャッシュの構成】
PIC32MXには、フラッシュメモリとCPUの命令バスの間にキャッシュメモリが追加
されています。これは、フラッシュメモリの動作が遅いため、80MHzのフルスピードでは
追従できないため、これをカバーするために用意されたものです。
このキャッシュメモリは下図のような構成となっています。
まずフラッシュメモリから命令を取り出す場合は、128ビット幅で取り出しますので、
32ビット幅の命令を4個同時に取り出すことができます。
命令実行はパイプライン動作となっていますので、プリフェッチサイクルのタイミングで
プリフェッチバッファに取り出し、それをキャッシュに転送します。
フラッシュメモリのアクセススピードは図にあるように30MHzが最大となっていますので、
それ以上のクロック周波数の場合にはウェイトステートを挿入してアクセス時間を確保
する必要があります。
プリフェッチバッファに4個の命令がありますから、これを実行している間にプリフェッチ
すればウェイトステートが2ステート挿入されても次のプリフェッチには間に合うことになります。
キャッシュメモリには、読み出した128ビット幅の命令を16段まで格納できるようになって
いますので、合計で4命令×16 = 64個の32ビット命令をキャッシュに格納した状態で
命令が実行されることになります。
キャッシュメモリからの命令取り出しは80MHzでもノーウェイトで取り出せるようになって
いますので、キャッシュから命令を実行する場合には最高速度が出せることになります。
このキャッシュメモリは命令だけでなく、フラッシュメモリ内にあるデータをアクセスする
場合にも有効で、ウェイトステート挿入による遅れを最小にできます。
注意が必要なことは、このプリフェッチメモリとキャッシュメモリはデフォルト状態では
無効になっていて使わず、直接フラッシュメモリから命令を読み出して実行します。
したがって、8倍程度実行速度がフルスピード状態より遅い実行速度となってしまいます。
【キャッシュの効果の確認】
実際にキャッシュの効果を確認してみました。
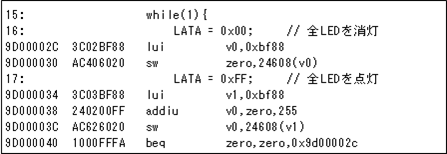
まず下記のようなプログラムを作ってみました。このプログラムはPORTAを
最高速度でオンオフするだけになっていますので、PORTAのピンには
最高速度でのパルスが出力されるはずです。
このプログラムのコンパイル結果は、メインループの部分は下記のように
なりました。このプログラムを解析すると、ループは全部で6個のアセンブラ
命令から構成されており、7サイクルで動作します。
したがって、80MHzのクロックで動作させた場合には、
12.5nsec×7 = 87.5nsec つまり 約11.43MHz
の繰り返しパルスとなるはずです。
しかし、このプログラムの実行結果は1.42MHzとなり、ちょうど8倍遅い
繰り返しパルスとなってしまいました。
ここで、元のプログラムでコメントアウトされている
SYSTEMConfigPerformance() という関数のコメントアウトをはずして
再コンパイルした結果は、期待通りの11.43MHzのパルスとなりました。
つまり、デフォルトではキャッシュは無効になっていますので、ウェイトステート
が挿入され、さらにプリフェッチバッファも無効になっています。これらの遅れに
より8倍遅くなっていたことになり、上記関数により最適化が行われ最大速度
になるように設定され、キャッシュやプリフェッチバッファが有効化されたことに
なります。
このSYSTEMConfigPerformance()という関数は便利な関数で、周辺モジュール
用ライブラリ関数として用意されている関数です。
SYSTEMConfigPerformance(80000000);
と記述すれば80MHzで最高性能が出るように、周辺用クロック(PBCLK)のクロック
デバイダの設定やキャッシュの設定、ウェイトステート設定などを自動的に最適な
状態にセットしてくれます。詳細は下記ドキュメントを参照して下さい。
「32-bit-Peripheral-Library-Guide.pdf」
このドキュメントはMPLAB C32コンパイラをインストールすると生成されるフォルダの
docフォルダ内に自動生成されます。